Elasticsearch-Kafka-Grafana


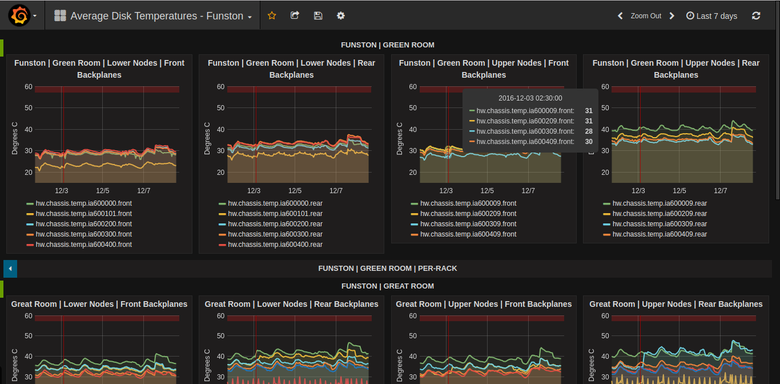

Client: One of the giants among the internet companies What is done: 1. Implementation and monitoring of Elasticsearch-Kafka pipeline - Here I made use of Kafka’s distributed nature to increase parallelism and improve on indexing rate for ES - Kafka is used as a buffer to make Logs-to-ES pipeline run smoothly, help with sudden spikes on log generation side and downtime on ES side - Handling multiple types of logs in the Kafka pipeline, for many different ES consumers. 2. Monitoring the cluster using Telegraph-InfluxDB-Grafana stack. Monitor load on each node (cpu/ram/disk) and alert using

Mi perfil
I have 18 yoe in ML, Big Data, BI and related data science works. Focused on helping a few niche technology companies in bringing their (mostly disruptive) ideas to life. A design thinker, responsive and collaborative individual with strong background in data science. My clients engage me to architect and develop solutions that have Big Data and/or Machine Learning as differentiating components. - Predictive Analytics & ML - Big Data Backends - Streaming Data Pipelines - Good Old ETL & BI Machine Learning: Regression, Association (apriori), Classification (decision trees, random forest, logit), Clustering (k-means) Python, Scikit-learn Dataiku, RapidMiner, Azure ML Studio, SageMaker Data Visualisation: Power BI, Tableau, Qlik, Klipfolio, Kibana DW and ETL: Snowflake, BigQuery, Athena, AirFlow, SSIS Stream Processing: Spark, Flume, Kafka, Kafka Streams, Kinesis Elasticsearch (ELK) I believe in simple and future-proof design. Putting trust and satisfaction before money.